
I am a postdoctoral fellow from the University of Chinese Academy of Sciences (UCAS). My research interests include vision-and-language and multimedia content analysis. You can find my CV here.
I received my doctoral degree from UCAS in 2025, advised by Prof. Li Su and Prof. Liang Li (ICT, CAS). I received my master’s degree from Kunming University of Science and Technology in 2022, advised by Prof. Zhengtao Yu. I received my bachelor’s degree from Hangzhou Dianzi University in 2018, advised by Prof. Chenggang Yan. I was lucky to have opportunities to collaborate with Assoc. Prof. Xishan Zhang (ICT, CAS) and Prof. Xingzheng Wang (Shenzhen University). Feel free to reach out to me if you have an interest in the relevant topics.
🔥 News
- 2025.11: A paper is accepted by IEEE TMM. Congrats to Zhuo Tao!
- 2025.09: A paper is accepted by IEEE TVCG. Congrats to Minghao Liu!
- 2025.09: A paper is accepted by NeurIPS 2025. Congrats to Junxi Chen!
- 2025.05: A paper is accepted by ACL 2025 Findings (long paper). Congrats to Yi Li!
- 2025.04: I will be serving as an Area Chair for ACM MM 2025.
- 2025.04: I will be serving as an Area Chair for EMNLP 2025.
- 2025.02: I will be serving as an Area Chair for ACL 2025.
- 2025.01: Selected for the Inaugural Doctoral Student Program under the Young Elite Scientists Sponsorship Program by CAST. (入选首届中国科协青年人才托举工程博士生专项计划,托举学会:中国计算机学会)
- 2024.12: Two papers are accepted by AAAI 2025. Congrats to Shijie Li!
- 2024.07: A paper is accepted by ECCV 2024.
- 2024.07: A paper is accepted by ACM MM 2024. Congrats to Shijie Li!
- 2024.07: A paper is accepted by IEEE TMM. Congrats to Yiting Liu!
- 2024.07: A paper is accepted by ECAI 2024. Congrats to Shijie Li!
- 2024.05: A paper is accepted by ACL 2024 main conference (long paper).
📝 Publications
Selected publications are listed below, focusing on three primary research tasks: hierarchical retrieval and step-captioning, image difference captioning, and video captioning. The full list is available on .
📚 Hierarchical Retrieval and Step-captioning
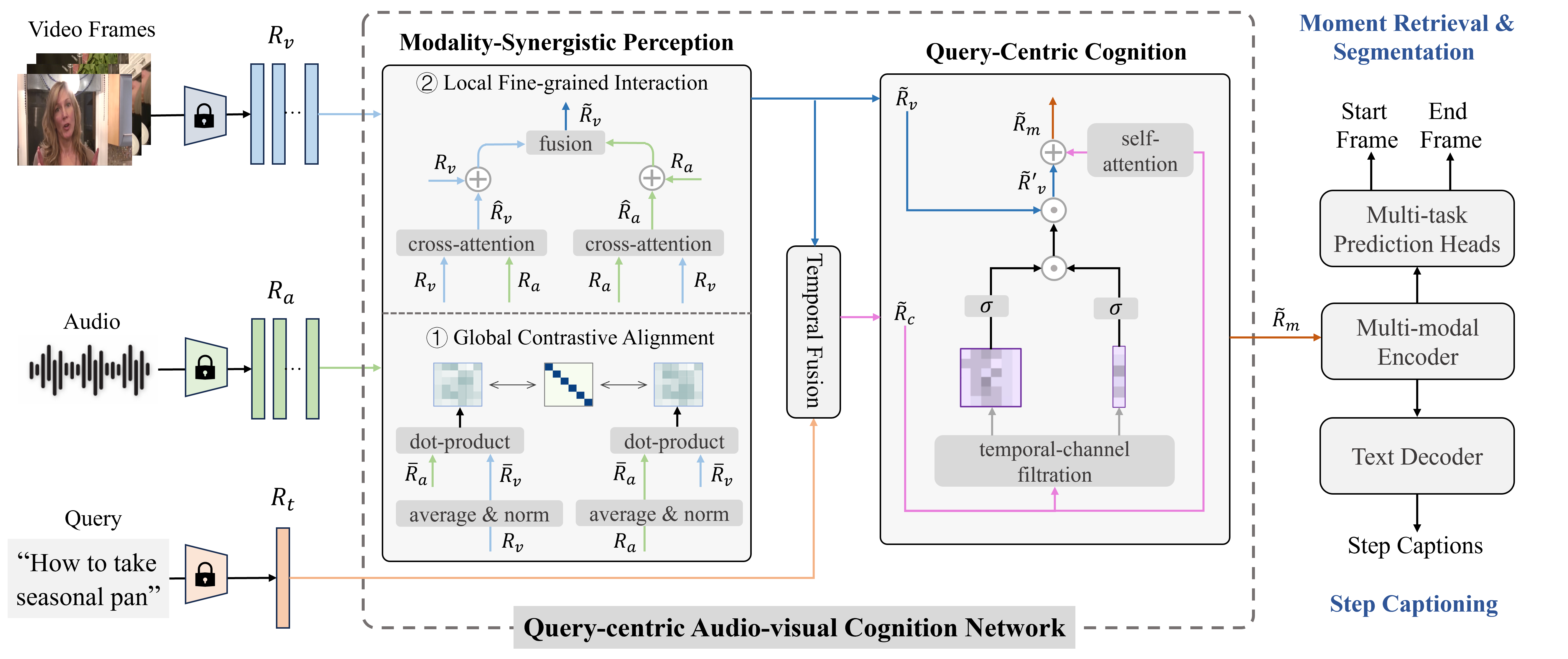
Query-centric Audio-Visual Cognition Network for Moment Retrieval, Segmentation and Step-Captioning [Code]
Yunbin Tu, Liang Li, Li Su, Qingming Huang
- QUAG addresses moment retrieval, moment segmentation, and step captioning in a unified framework.
- QUAG learns a query-centric audio-visual representation based on the shallow-to-deep principle.
🖼️ Image Difference Captioning (Change Captioning)
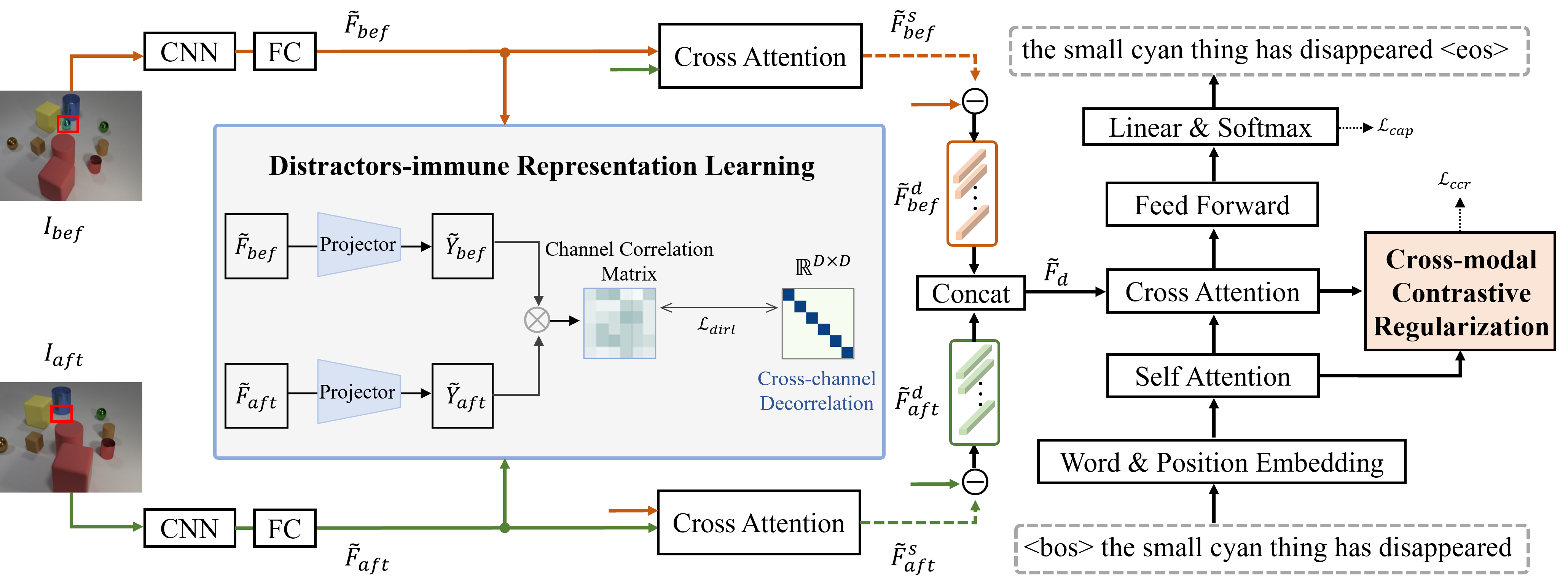
Distractors-Immune Representation Learning with Cross-modal Contrastive Regularization for Change Captioning [Code] [Supp.]
Yunbin Tu, Liang Li, Li Su, Chenggang Yan, Qingming Huang
- DIRL attains a pair of stable image representations by correlating the corresponding their channels and decorrelating different ones.
- CCR regularizes the cross-modal alignment by maximizing the contrastive alignment between the attended difference features and generated words.
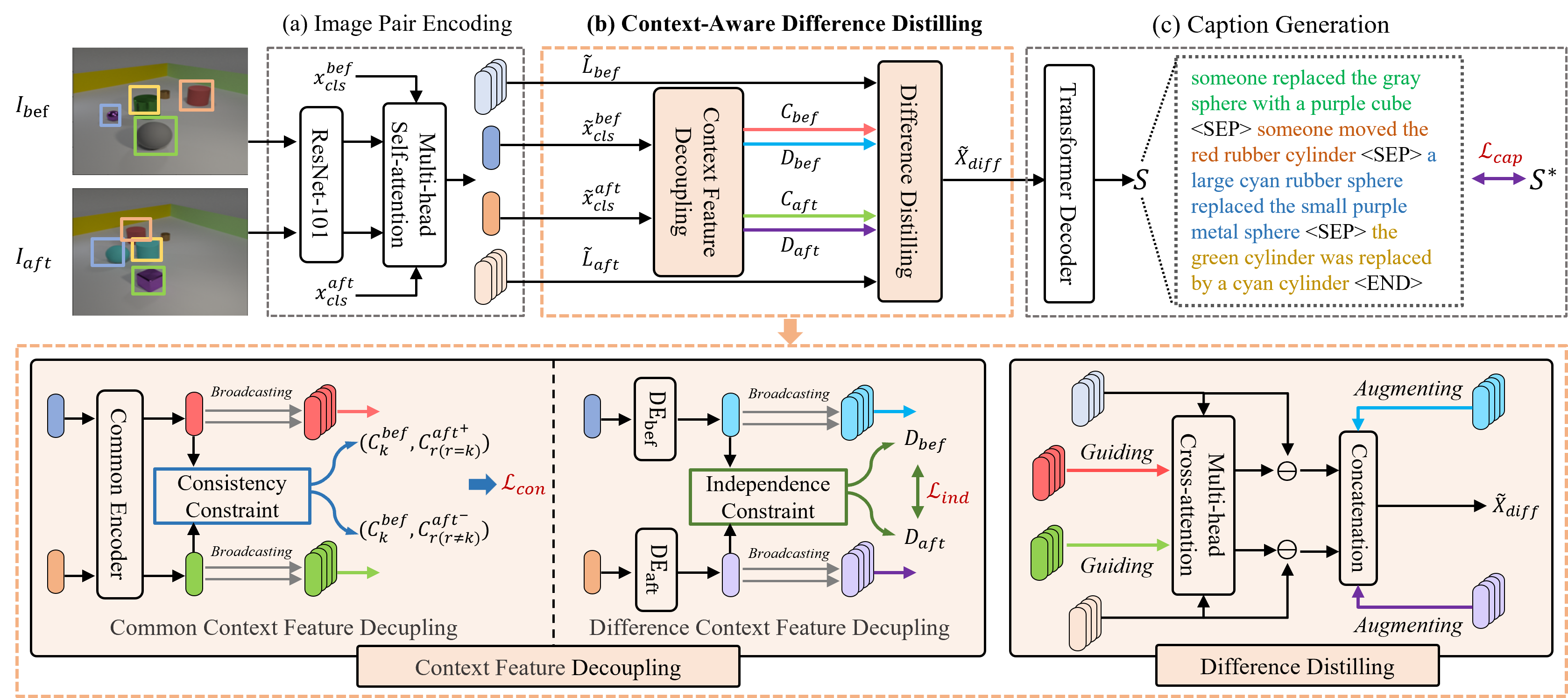
Context-aware Difference Distilling for Multi-change Captioning [Code]
Yunbin Tu, Liang Li, Li Su, Zheng-Jun Zha, Chenggang Yan, Qingming Huang
- CARD addresses multi-change captioning with an unknown number of changes.
- CARD decouples common/difference context features to guide the learning of features of all genuine changes for generating corresponding sentences.
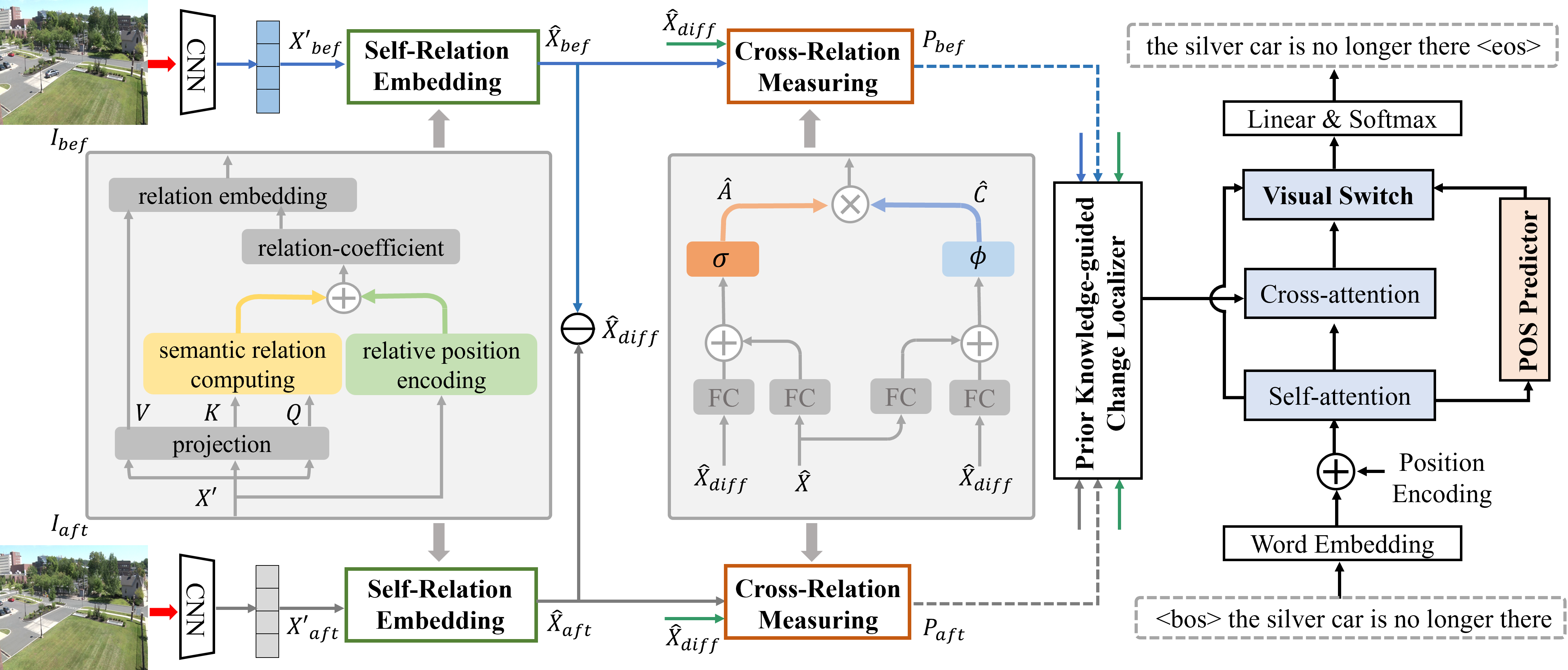
| SMART: Syntax-calibrated Multi-Aspect Relation Transformer for Change Captioning [Code] | Extension work of SRDRL (ACL Findings 2021) |
Yunbin Tu, Liang Li, Li Su, Zheng-Jun Zha, Qingming Huang
- SMART uses a multi-aspect relation learning network to learn effective change features for caption generation.
- SMART uses a POS-based visual switch to dynamically use visual information during different word generation.
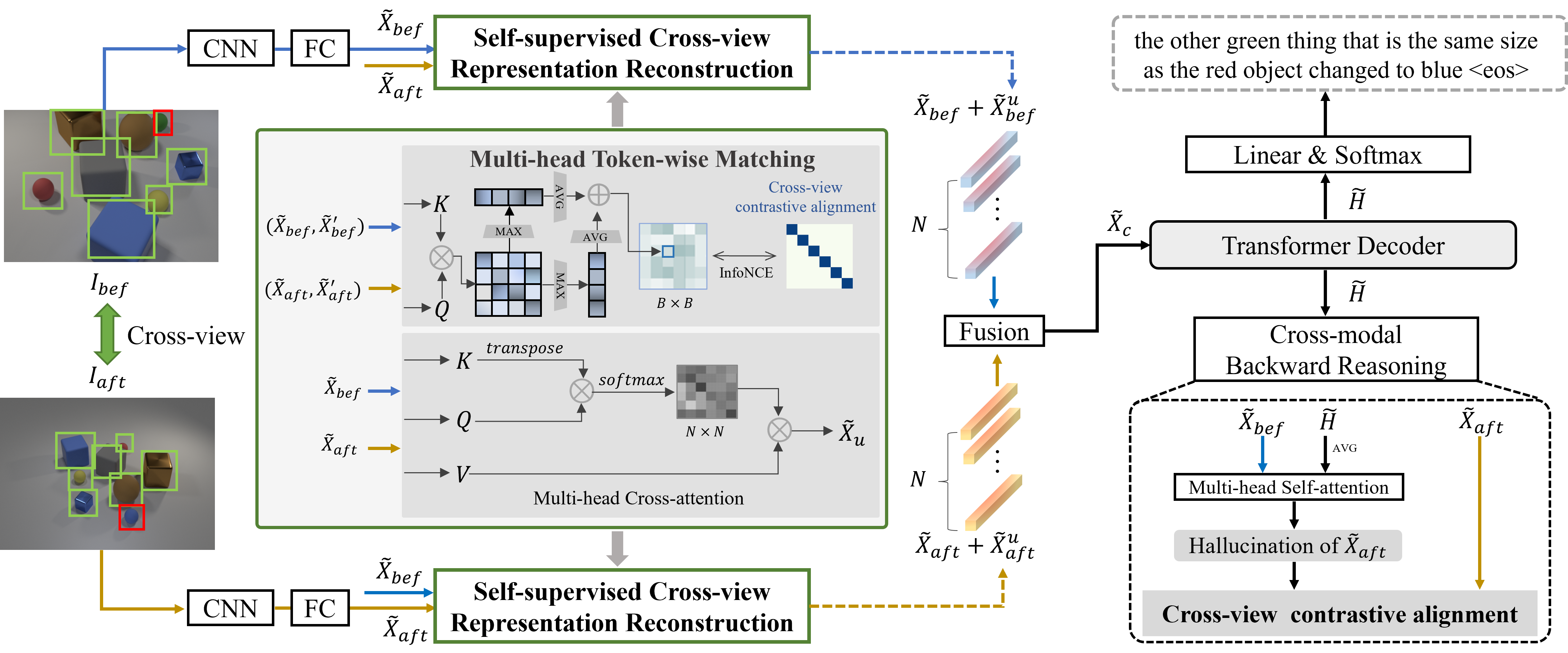
Self-supervised Cross-view Representation Reconstruction for Change Captioning [Code] [Supp.]
Yunbin Tu, Liang Li, Li Su, Zheng-Jun Zha, Chenggang Yan, Qingming Huang
- SCORER learns two view-invariant image representations by by maximizing cross-view contrastive alignment of two similar images.
- CBR reversely models a “hallucination” representation with the caption and “before” image, and matchs it with the real “after” image.
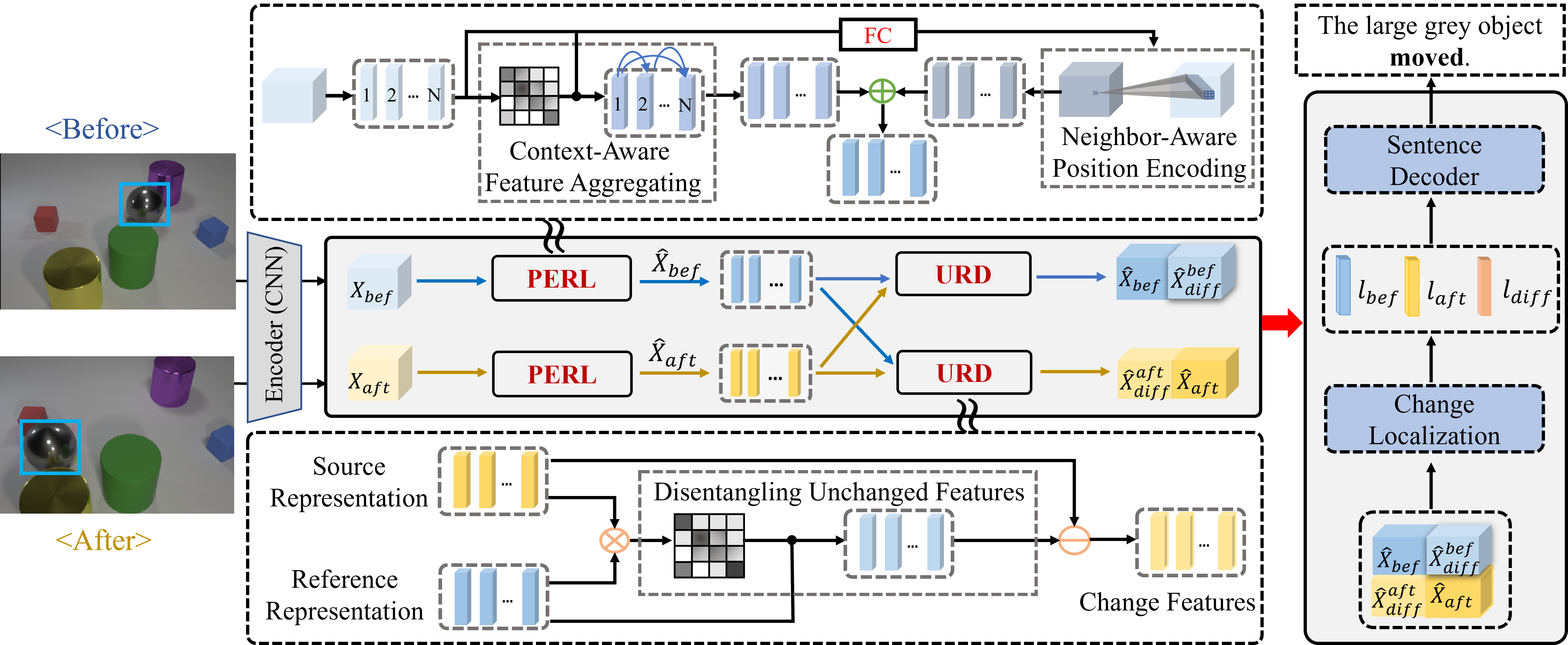
Viewpoint-Adaptive Representation Disentanglement Network for Change Captioning [Code]
Yunbin Tu, Liang Li, Li Su, Junping Du, Ke Lu, Qingming Huang
- VARD helps the model adapt to viewpoint changes via mining the intrinsic properties of two images and modeling their position information.
- VARD uses an unchanged representation disentanglement to distinguish the unchanged features from changed features.
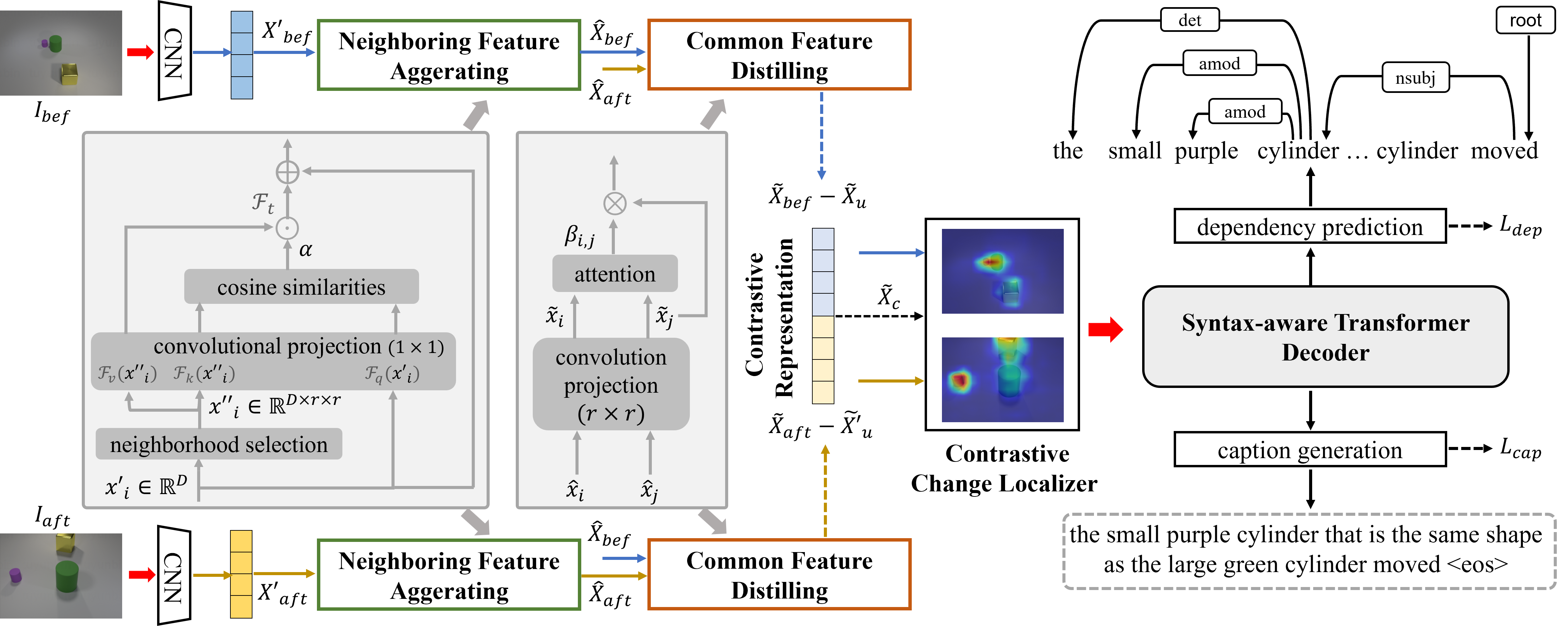
Neighborhood Contrastive Transformer for Change Captioning [Code]
Yunbin Tu, Liang Li, Li Su, Ke Lu, Qingming Huang
- NCT learns the contrast features between two images via a neighboring feature aggregating and a common feature distilling.
- Explicit dependencies between words is used to help the decoder to better understand complex syntax structure during training.
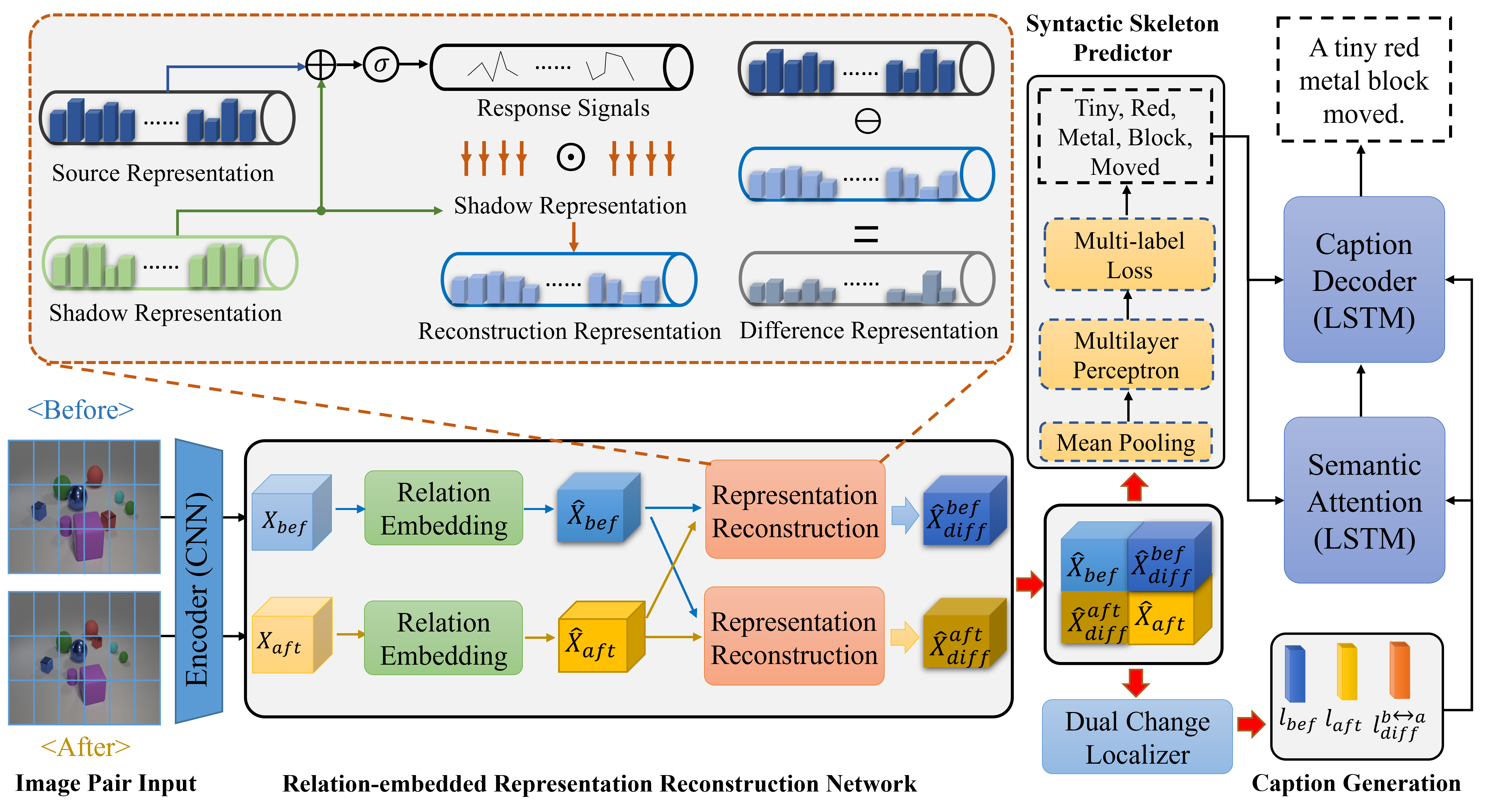
R3Net: Relation-embedded Representation Reconstruction Network for Change Captioning [Code] [Video]
Yunbin Tu, Liang Li, Chenggang Yan, Shengxiang Gao, Zhengtao Yu
- R3Net learns relations within each image and between two images to reconstruct unchanged and changed features.
- R3Net uses syntactic skeleton predictor to enhance semantic interaction between change localization and caption generation.
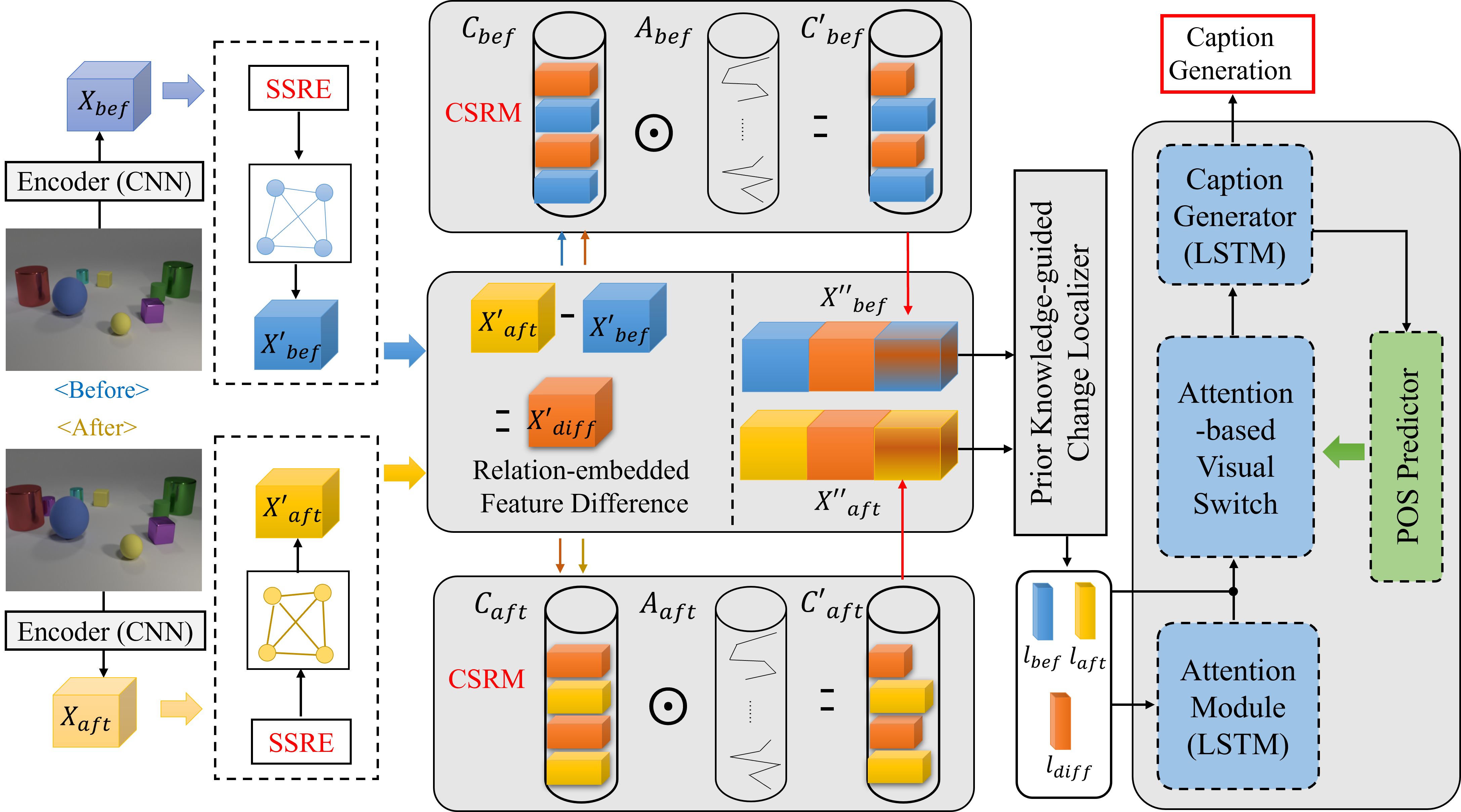
Semantic Relation-aware Difference Representation Learning for Change Captioning [Code] [Video]
Yunbin Tu, Tingting Yao, Liang Li, Jiedong Lou, Shengxiang Gao, Zhengtao Yu, Chenggang Yan
- SRDRL models self-semantic relation to explore the underlying changes, and measures cross-semantic relation to localize the real change.
- SRDRL relys on the POS of words, and uses an attention-based visual switch to dynamically use visual information for caption generation.
🎞️ Video Captioning
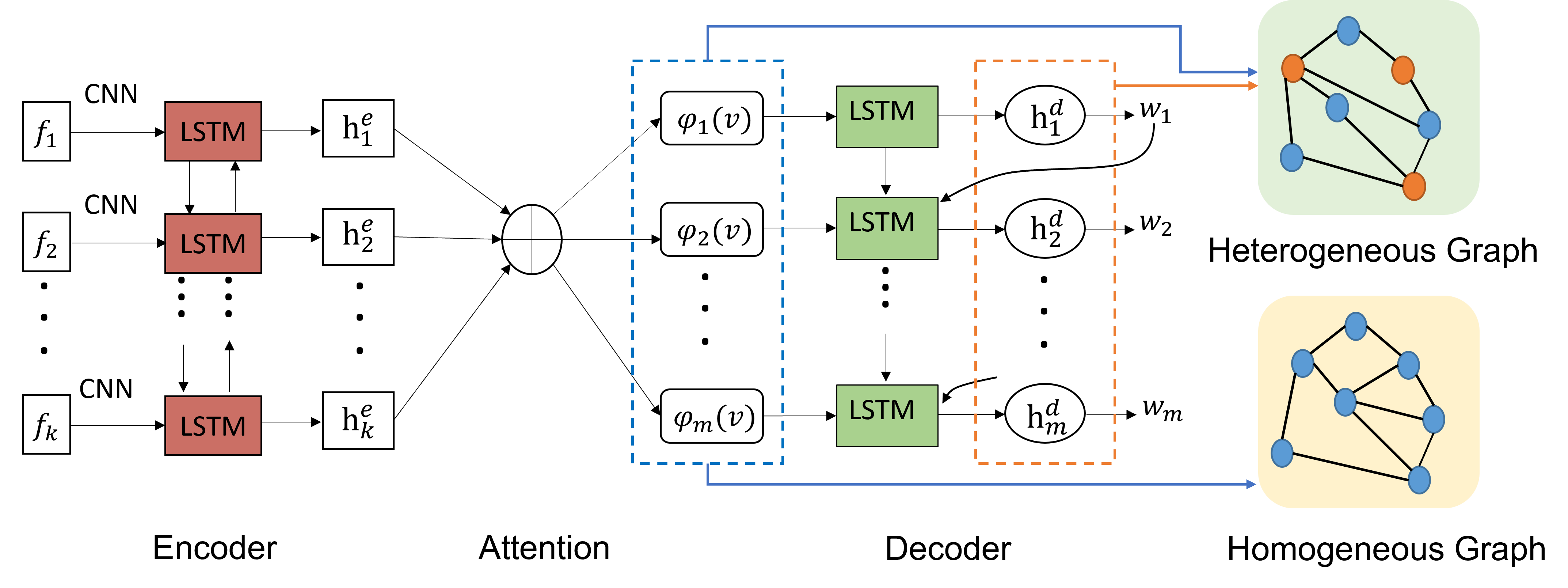
Relation-aware Attention for Video Captioning via Graph Learning
Yunbin Tu, Chang Zhou, Junjun Guo, Huafeng Li, Shengxiang Gao, Zhengtao Yu
- HTG aims to enhance the inter-relation of attention by reversely modeling the relation of each word with respect to every attended visual feature.
- HMG aims to enhance the intra-relation of attention by capturing the relations among all of the attended visual features.
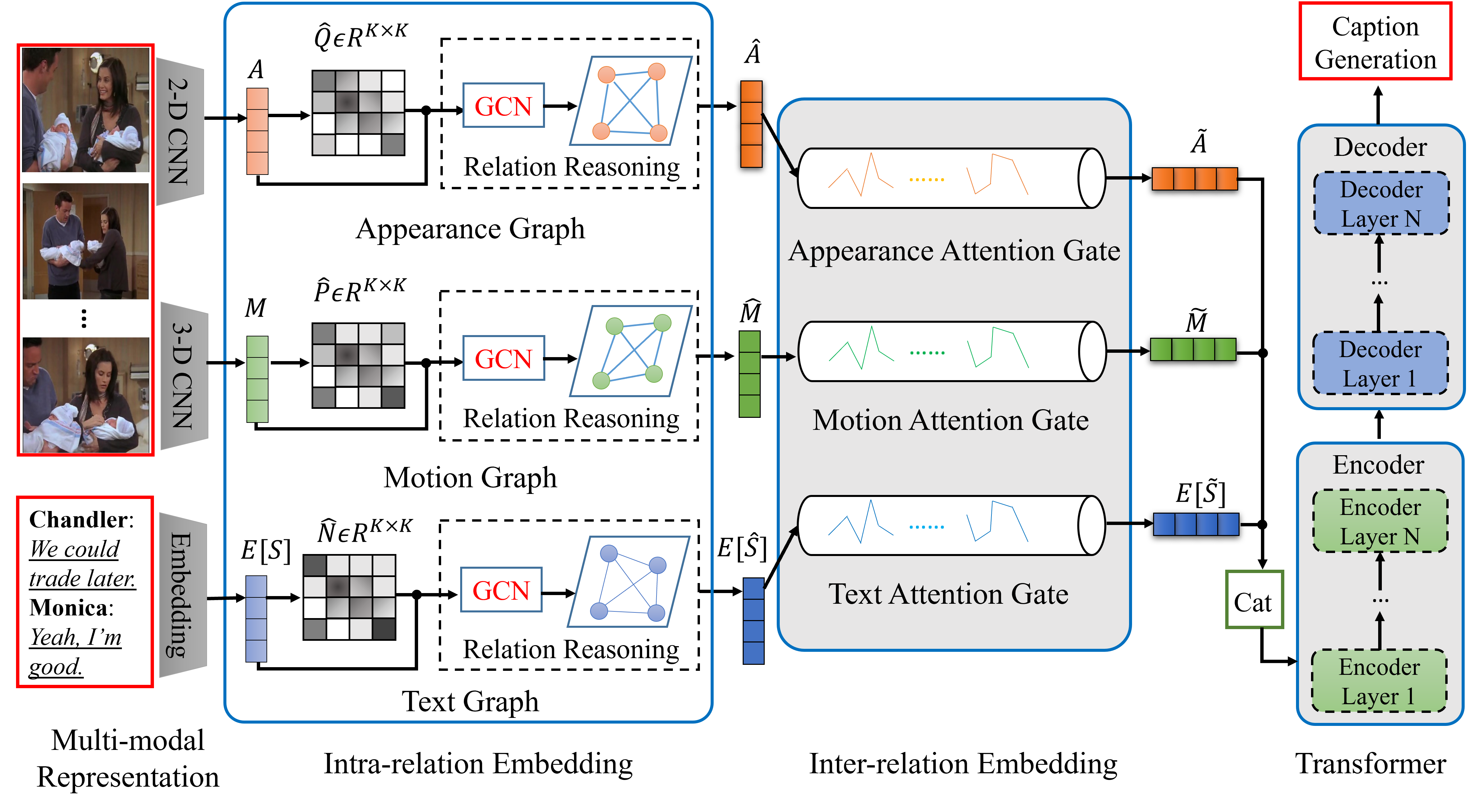
I2Transformer: Intra- and Inter-relation Embedding Transformer for TV Show Captioning [Code]
Yunbin Tu, Li Su, Shengxiang Gao, Chenggang Yan, Zheng-Jun Zha, Zhengtao Yu, Qingming Huang
- TV show captioning aims to generate a linguistic sentence based on the video and its associated subtitle.
- I2Transformer uses an intra-relation embedding to capture intra-relation in each modality and an inter-relation embedding to produce the omni-representation of all modalities.
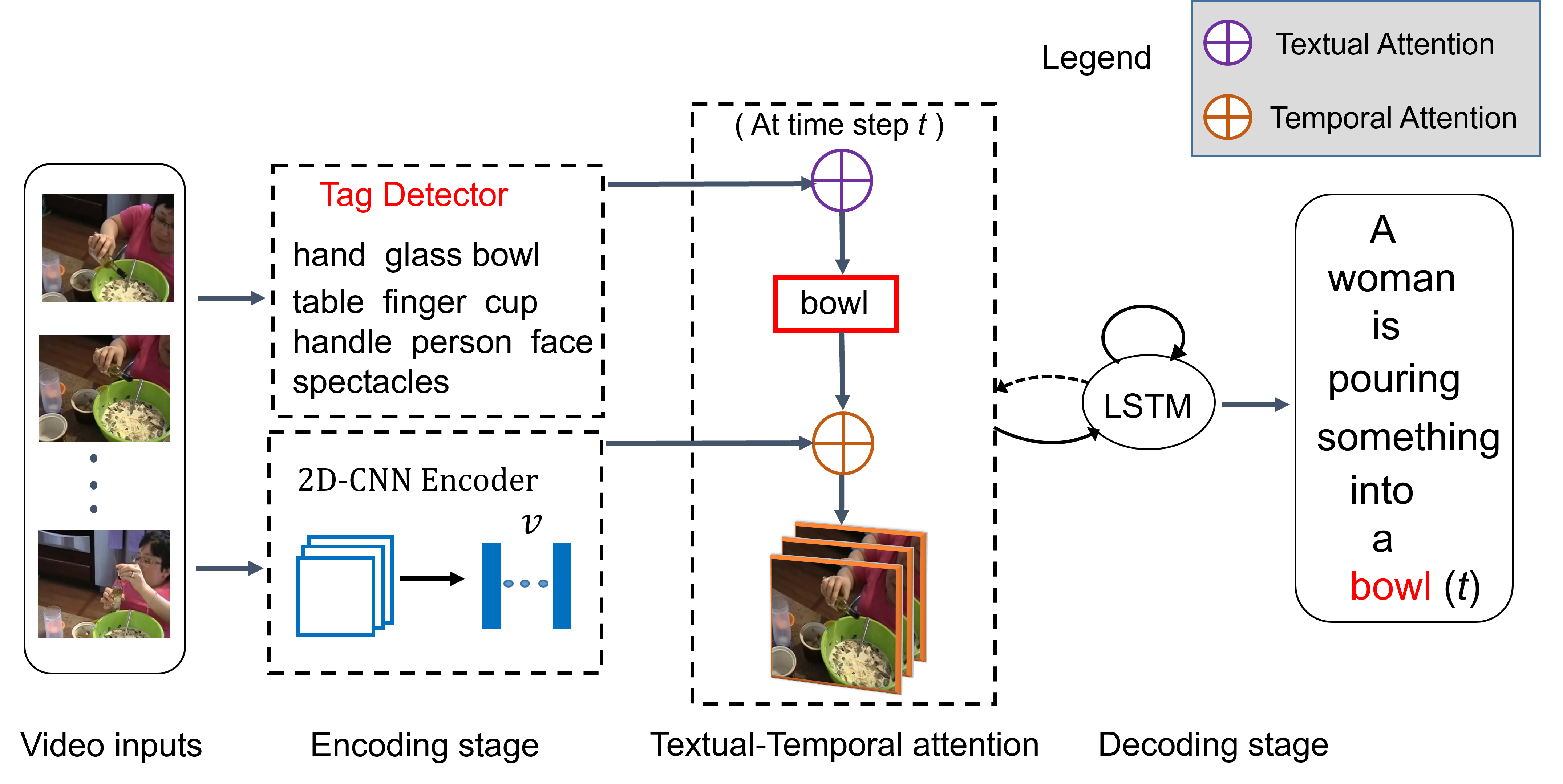
Enhancing the alignment between target words and corresponding frames for video captioning [Code]
Yunbin Tu, Chang Zhou, Junjun Guo, Shengxiang Gao, Zhengtao Yu
- TTA uses pre-detected visual tags from the video to bridge the gap between vision and language.
- TTA exactly align the target words with corresponding frames guided by the visual tags.
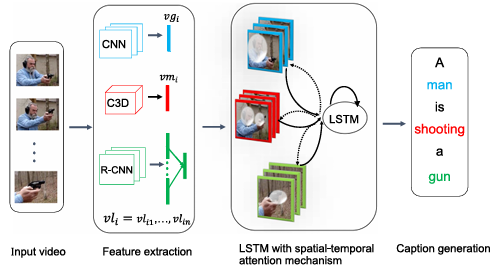
| STAT: Spatial-Temporal Attention Mechanism for Video Captioning [Code] | Extension work of STAT (ACM MM 2017) |
Chenggang Yan, Yunbin Tu, Xingzheng Wang, Yongbing Zhang, Xinhong Hao, Yongdong Zhang, Qionghai Dai
- STAT uses both object-level visual and label features to address the problem of detail missing.
- STAT successfully takes into account both the spatial and temporal structures in a video.
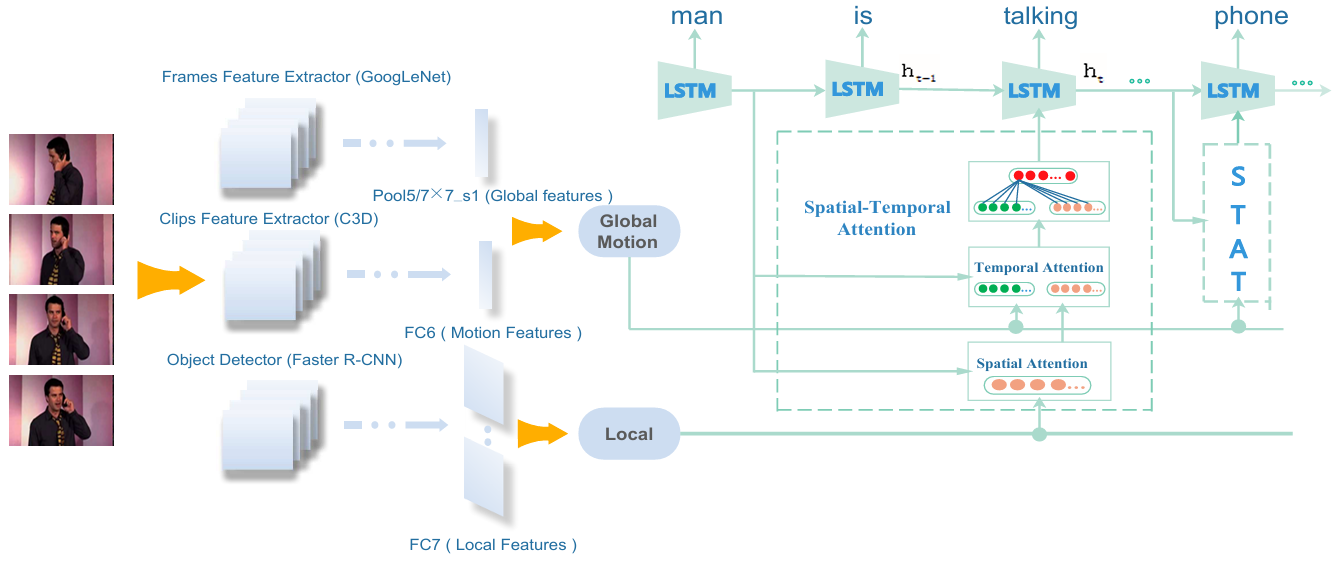
Video Description with Spatial-Temporal Attention [Code]
Yunbin Tu, Xishan Zhang, Bingtao Liu, Chenggang Yan
- STAT uses object-level local features to address the problem of detail missing.
- STAT selects relevant local features by spatial attention and then attend to important frames by temporal attention to recognize related semantics.
🏆 Honors and Awards
- The Inaugural Doctoral Student Program under the Young Elite Scientists Sponsorship Program, China Association for Science and Technology, 2025. (首届中国科协青年人才托举工程博士生专项计划,托举学会:中国计算机学会)
- CAS President Scholarship (Excellent Prize), 2025. (中国科学院院长优秀奖)
- AAAI Student Scholarship, 2025.
- National Scholarship for Doctoral Students, Ministry of Education of the People’s Republic of China, 2024.
- Diversity and Inclusion Award, Annual Meeting of the Association for Computational Linguistics (ACL), 2024.
- National Scholarship for Master’s Students, Ministry of Education of the People’s Republic of China, 2021.
- Student Travel Grant, ACM International Conference on Multimedia (ACM MM), 2017.
📖 Educations
- 2022 - 2025, Ph.D. in Computer Applied Technology, University of Chinese Academy of Sciences (UCAS), China.
- 2019 – 2022, M.S. in Pattern Recognition and Intelligent Systems, Kunming University of Science and Technology (KUST), China.
- 2014 – 2018, B.S. in Automation, Hangzhou Dianzi University (HDU), China.
👨🏫 Academic Services
- Area Chair of ACL 2025 / EMNLP 2025 / ACM MM 2025
- Journal Reviewer of TPAMI / TIP / TMM / TCSVT / PR / CVIU …
- Conference Reviewer of ICCV / CVPR / ECCV / NeurIPS / AAAI / ICLR …